Mahout推荐系统源码分析
author: sheng junhui
weibo: @armysheng
blog: youngfor.me
email: armysheng@gmail.com
Mahout下个性化推荐引擎Taste介绍
以下讨论基于Mahout 版本 version0.9
本文关心的是如何利用Mahout在非分布式,非Hadoop based 情况下(即单机模式下)建立一个协同滤波的推荐系统。 Taste曾经是一个独立的项目,现在在Mahout和其他基于Hadoop的项目中发展。相对与目前的研究重点*--如何将推荐算法在Hadoop等分布式计算上实现--*Taste项目可以是一个更加独立,更加综合,更加稳定的项目。也被认为是学习和理解Mahout推荐引擎的基本入门点。 基于系协同滤波的Mahout推荐引擎可以通过用户对某些物品的喜好的计算,来得到用户对另一些物品的喜好。比如说一个卖书或者CD的网站,可以个根据用户以往的购买经历和喜好等数据,轻松的利用Mahout来得到用户对其他的那些书或者CD感兴趣。
Mahout提供了一组丰富的组件,您可以选择特定的算法构建一个定制的推荐系统。并且Mahout设计时考虑到了企业级的应用,高性能、可伸缩性和灵活性。
在构建推荐系统是,Mahout的顶层的packages中用到的接口有这些:
- DataModel
- UserSimilarity
- ItemSimilarity
- UserNeighborhood
- Recommender
在org.apache.mahout.cf.taste.impl这个包中有对这些接口的实现。所有这些包就是你在搭建自己的推荐系统时需要用到的。
架构图:
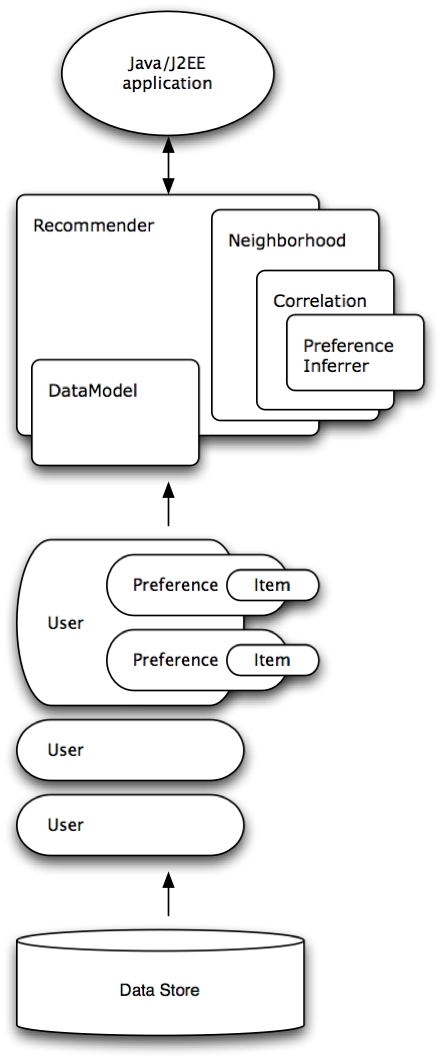 改图显示了在一个Userbased 推荐器中,各个Mahout组件之间的关系。Item-base的推荐系统也与之类似,只是不包含Neighborhood算法。
改图显示了在一个Userbased 推荐器中,各个Mahout组件之间的关系。Item-base的推荐系统也与之类似,只是不包含Neighborhood算法。
标准化的开发过程
以UserCF的推荐算法为例,官方建议我们的开发过程:

图片摘自Mahout in Action
从上图中我们可以看到,算法是被模块化的,通过1,2,3,4的过程进行方法调用。我们可以使用如下的简单代码来实现一个User-based CF算法。
我们用到的4个类有DataModel, UserSimilarity, NearestNUserNeighborhood, Recommender。下面我们来逐个介绍一下这些类。
DataModel
DataModel是关于用户偏好信息的一个借口。实现这个接口的数据可以是任何来源(单独的条目,文件,数据库等等),但是大多数情况下数据都来源于数据库。使用时应当与ReloadFromJDBCDataModel类结合来获得更好的性能。举例来说,Mahout提供了MySQLJDBCDataModel来获得JDBC和MySQL数据库中的用户偏好信息。同时还有对PostgreSQL的支持。Mahout 同样提供了一个FileDataModel类,可以非常方便的应用于规模较小的项目中。
在该模型中,用户和物品都是用一个唯一的ID号来辨识,而且这个ID还必须是在Java中long类型的数字。而其中的Preference或者PreferenceArray对象者封装了用户和物品直接的关系(即物品,和用户对物品的喜爱度)。
最后,Mahout还有对布尔量数据模型的支持,该模型用户没有对某一物品进行特定的评分,而只是单纯的判断他们之间有没有建立某种联系。举例来说,某用户在一些电影推荐的网站上,可能可以对电影进行1~5星的评分。但是对于某个网站(比如说亚马逊)的推荐页,用户可能没有办法对这个推荐页的好坏进行评分,但是我们可以通过或缺用户是否访问了推荐的产品,即用户与推荐页是否建立了联系来建立DataModel。
Mahout0.9版本中Datamodel的类图(缩放页面查看大图)如下:

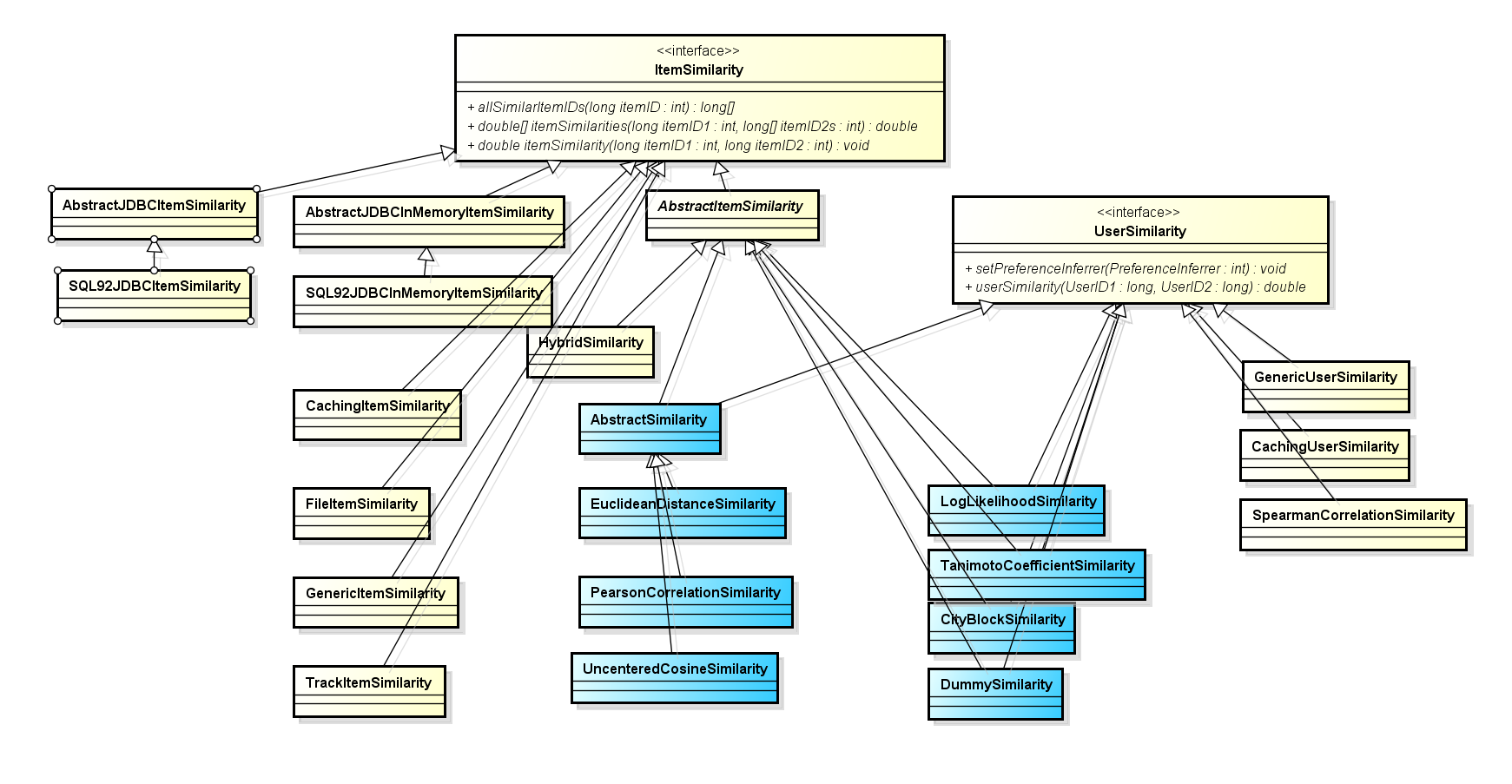
UserSimilarity&&ItemSimilarity
UserSimilarity定义了两个用户之间的相似度。只是推荐引擎的关键部分,也是目前推荐系统研究性能提高的关键点。这也是Neighborhood类寻找近邻的基础。Neighborhood也类似,是用来寻找物品之间的相似度。
Mahout0.9版本中相关的类图(缩放页面查看大图)如下:
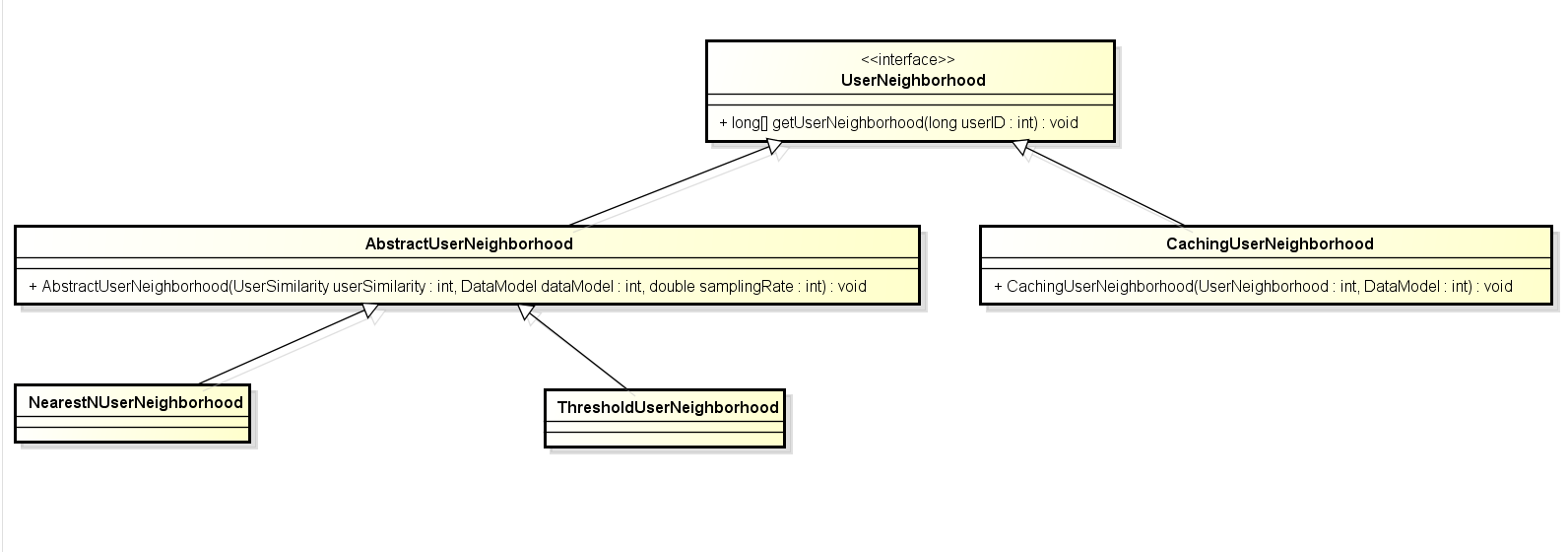
UserNeighborhood
在一个user-based 推荐系统中,相关的推荐是通过找到某一用户的相似用户,即“近邻”。
一个UserNeighborhood通过某种特定的手段得到一些邻近的用户,比如说最近的10用户、相似度大于0.8的用户。
通常UserNeighborhood的实现需要UserSimilarity作为入口。
Mahout0.9版本中相关的类图(缩放页面查看大图)如下:
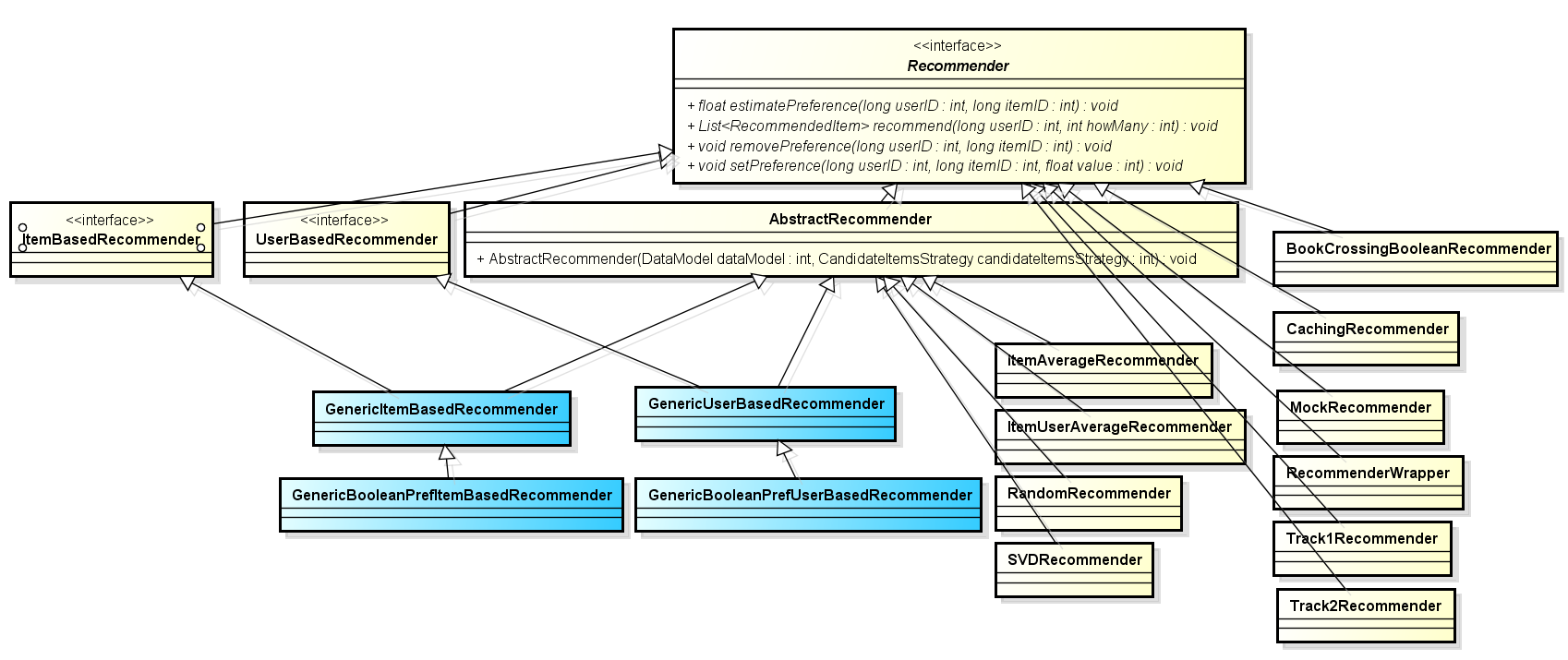
Recommender
Recommender是Mahout核心的抽象类。对于一个DataModel,该类能够构造一个推荐器。项目中我们大部分情况下会用到
GenericUserBasedRecommender or GenericItemBasedRecommender来产生userbased以及Itembased 协同滤波推荐器,同时可能结合了 CachingRecommender。
Mahout0.9版本中相关的类图(缩放页面查看大图)如下:
结尾
至此我们就介绍完了构造一个推荐系统所需要的一些类和接口,我们可以通过分析它更底层的代码,来进一步了解推荐系统实现的细节。

